Recently I had to make some updates to DornerWorks VirtuosityTM Bare Metal Container. Virtuosity is our open source and actively supported collection of software components and tools for the Zynq Ultrascale+ MPSoC; everything you need to get a Xen based system up and running quickly while providing you the tools to make your own additions. The Bare Metal Container is piece of code and a build script we wrote that creates an environment for standalone applications, such as you might create using the Xilinx SDK, to run in as guests. One of the key things it does is sets up the MMU to perform the virtual address translation, and I had to change that code in order to be able to map in more memory regions. I had to learn about how the MMU works on the ARMv8 processor and thought I would share what I found out.
You may already know that the basic purpose of the MMU is to translate the virtual address (VA) to a physical address (PA). You may not know that on the ARMv8 there are actually two stages of mapping, called translation regimes, that take you from VA to the guest’s, or intermediate, physical address (IPA), and then from that IPA to the PA. Luckily for our purposes, the Xen hypervisor is responsible for setting up the IPA to PA translation, so from the guest’s perspective, it looks like the IPA is the PA, so we just need to concern ourselves with setting up the tables to translate the VA to the IPA.
Another interesting, and very useful, feature of the ARMv8 MMU is that it uses different memory tables to define the VA:IPA or IPA:PA translations for the different Exception Levels (EL), which is ARM’s way of saying privilege level. This allows different VA to PA mappings depending on what’s running. In our example, the hypervisor running at EL2 follows a set of translation rules unique to it, while the guest, running at EL1, uses a different set. Since Xen is responsible for those EL2 mappings, I will focus on explaining how the EL1, stage 1 translations work. The same concepts explained below are applicable to the other variations (EL2, stage2).
The first thing to understand about how the MMU works on the ARMv8 is that it actually has two sets of page tables. Which set is used is determined by where the VA being translated falls in the address map. If the most significant bits of the address are 0, then the translation table specified in the translation table base register 0 (TTBR0) is used. If the most significant bits are 1, then translation table specified in the translation table base register 0 (TTBR1) is used. These two address ranges are somewhat configurable by setting the TxSZ attributes in the TCR_EL1 register. The range covered by TTBR0 goes from 0 to 264-T0SZ-1, and the range covered by TTBR1 from 264-264-T1SZ to 264-1.
Walking the Tables
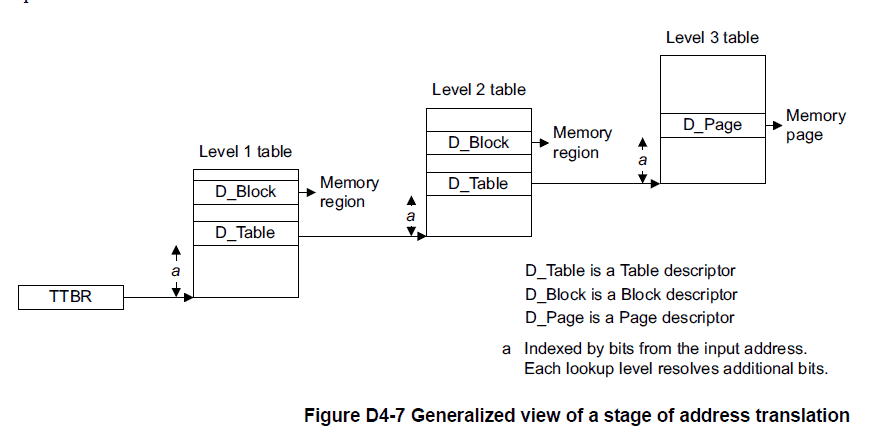
Translating a virtual address to a physical address, or in my case an intermediate physical address, is performed automatically by the hardware by reading the information from appropriate translation table base register, for the purpose of this explanation TTBR0, and is called a translation table walk. However, putting all of the translation information necessary to get a 4KB page granularity into a single table requires a lot of space, 1GB for a 39 bit address space, which is a lot of memory to use if you only want to use a single 4KB page out of the memory region. The ARMv8 MMU allows for efficient structuring by having multiple levels of lookup tables, a maximum of 4 for the ARMv8 (although we only use 3 in our Bare Metal Container), with each table providing further refinement, if necessary, by holding a pointer to the base of the next level translation table. If not, than in any table after level 0, the entry can define the base IPA for an entire block, either 1GB or 2MB depending if the block is defined in a level-1 or level-2 table respectively. Decreasingly significant sets of 9 bits from the virtual address are used to calculate an offset from the table base to quickly get the table entry appropriate to the VA at that level.
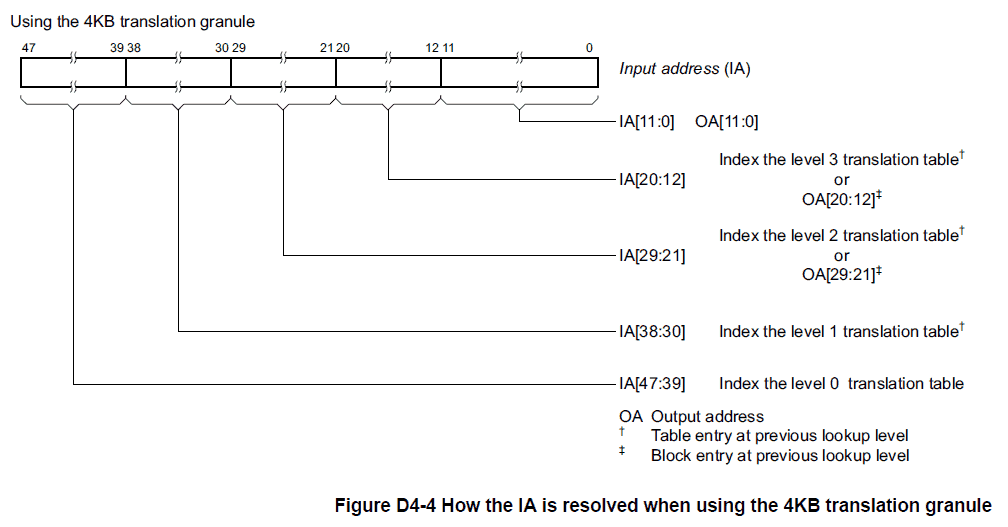
Figure D4-4 from the ARMv8 Architecture Reference shows which bits are used to index into a specific level’s table. For the Bare Metal Container, since only 39 bits are used for the VA, we don’t use the level 0 translation table, and TTBR0 holds the base address of the level-1 table. As figure D4-4 shows, bits 38:30 are used to index into the table. The entry at that location will either be a block, giving the upper bits of the (I)PA translation along with some other data to define an entire 1GB region of translation, or it will hold the base address of a level-2 table that will be used to further refine the 1GB space into smaller, 2MB spaces. The level-2 table is indexed by bits 29:21 of the virtual address, and again the entry can either be a block, which would define how any address in that 2MB region would be translated, or the base address of a level-3 table. The level-3 table is indexed by bits 20:12 of the virtual address. At this last level an entry has to define how the 4KB page translates.
As a quick example, imagine a virtual address of 0xFF010000 is to be translated. First, TTBR0 would read to get the base of the level-1 table, for this example let’s say 0x40000000 (note that translation tables themselves are subject to MMU translations, it’s turtles all the way down). Bits 38:30 of the VA are b’11, or 3, so the 4th entry, offset 0 is the 1st entry, and each entry takes 8 bytes, so the entry at address 0x40000018 is used is used. If that entry is a block, defined by whether or not some of the least significant bits of the entry are set, the physical (intermediate or otherwise) address bits stored in the entry are used with the low order bit of the VA to determine the final address. However, if the entry is a table address, for example say 0x40001000, then the process repeats, this time using bits 29:21, or b’11111000, or 0x1F8, or the 505th entry at 0x40001FC0, near end of the 4KB table. Again, this entry could define a larger memory region, in this case 2MB, or it could hold the address for a level-3 table, for example 0x40002000, and the process repeats. This time bits 20:12 are used, which is b’1, so the 2nd entry at 0x40002008 is used, which must define a legal 4KB translation.
The interesting thing about this multi-level setup is that there is nothing to prevent you from using the same next level tables in different entries in the current table. If, for example, you know you only need a few MB from one 1GB region, and another few MB for another 1GB region, and you know as the software designer that these MB regions have a unique set of address bits 29:21, then you *could* set up your level-1 entries to all point to the same level-2 table. In fact, this is what the Linux assembly bootstrap code does. However, this scheme is very fragile, and it just takes the addition of a memory region that has an overlap in those address bits to throw everything off. From a maintainability perspective, it would be better to keep each entry in a translation table, at any level, pointing to a unique next level page table or defining a block translation. Even so, if the full range of VA to be used are known at design time, then all of the page tables can be set up during initialization before they are needed, allowing for a more consistent and predictable runtime operation.
However, if the full extent of the virtual addresses is not known at design time, a more flexible approach is needed. One such approach would be to dynamically allocate space for the page tables from the heap as they are needed. This would be the case each time a new GB, 2MB, or 4KB memory range needs to be mapped, and depending on the current mapping may require multiple levels of mapping, which would negatively impact performance for those cases, or could even result in a failure if no memory was available on the heap!
One last parting observation, because walking the tables require memory lookups, which themselves could require a memory lookup or result in cache shenanigans, the fewer table lookups required, the faster the translation goes. Opting to use a block in a lower level table to map a larger section of memory than actually required can prove to be beneficial, both in terms of speed and amount of memory tied up in translation tables. Because Xen provides precise PA:IPA mappings, you can add a block entry that maps a region that is larger than, but still includes, the memory region you are interested in. If the software tries to access a location mapped by the block (VA:IPA) but outside of what you want to allow it, as mapped by Xen (IPA:PA), it will still result in the desired exception. The only time you would really need to use lower level tables is when the translation data, either the output IPA address or memory properties need to be different for different sub-regions.
For example, if you were to map out a 1GB region (defined in the level-1 tables) down to the 4KB pages (defined in level-3 tables), then you would need to device the 1GB region into 512 2MB regions, costing one 4KB table, and then each of those 2MB regions divided up into 512 4KB regions, requiring an additional 2048 KB, for a grand total of 2052KB. Further, each access to an address in that 1GB region would, if the mapping wasn’t already cached in a TLB, require 3 table lookups. If instead you defined a 1GB block to cover the whole region, you would not need any additional tables, and the lookup would be limited to a single table. However, if you needed to configure the translations so that the first 4KB of every 2MB region had different caching properties or needed to be mapped to a different IPA, then you would be forced to use all 3 levels of tables.